推倒萬億參數(shù)大模型內(nèi)存墻 從第一性原理看神經(jīng)網(wǎng)絡(luò)量化、數(shù)據(jù)處理與存儲支持
隨著人工智能模型的參數(shù)規(guī)模突破萬億,內(nèi)存墻成為訓(xùn)練和部署大型神經(jīng)網(wǎng)絡(luò)的關(guān)鍵瓶頸。本文從第一性原理出發(fā),深入剖析神經(jīng)網(wǎng)絡(luò)量化的理論基礎(chǔ)與實踐路徑,并結(jié)合數(shù)據(jù)處理與存儲支持服務(wù),探討如何高效突破內(nèi)存限制,推動大模型技術(shù)的可持續(xù)發(fā)展。
一、內(nèi)存墻的挑戰(zhàn)與根源
內(nèi)存墻是指模型在訓(xùn)練和推理過程中,由于參數(shù)數(shù)量龐大,導(dǎo)致內(nèi)存帶寬和容量成為性能的主要限制因素。以萬億參數(shù)模型為例,如果使用32位浮點數(shù)存儲,僅參數(shù)就需占用約4TB內(nèi)存,遠超當(dāng)前硬件設(shè)備的常規(guī)配置。這不僅增加硬件成本,還拖慢計算速度,限制模型在邊緣設(shè)備上的部署。其根源在于傳統(tǒng)浮點表示法在精度和效率之間的不平衡,亟需通過量化技術(shù)優(yōu)化。
二、神經(jīng)網(wǎng)絡(luò)量化的第一性原理
量化旨在將高精度浮點參數(shù)轉(zhuǎn)換為低精度整數(shù)或定點數(shù),從而減少內(nèi)存占用和計算開銷。從信息論和數(shù)值分析的角度,量化可以視為一種有損壓縮過程,核心在于在保持模型性能的前提下,最小化信息損失。
- 理論基礎(chǔ):量化基于分布假設(shè)和誤差容忍性。神經(jīng)網(wǎng)絡(luò)的權(quán)重和激活值通常服從高斯或拉普拉斯分布,通過非均勻量化(如對數(shù)量化)或均勻量化,可以保留關(guān)鍵信息。第一性原理要求我們回歸本質(zhì):量化誤差的傳播必須控制在模型容錯范圍內(nèi),這涉及梯度分析、損失函數(shù)敏感度評估等。
- 實踐方法:包括后訓(xùn)練量化(PTQ)和量化感知訓(xùn)練(QAT)。PTQ直接對預(yù)訓(xùn)練模型進行量化,適用于快速部署;QAT在訓(xùn)練過程中模擬量化效應(yīng),提升模型魯棒性。例如,將32位浮點量化為8位整數(shù),可減少75%的內(nèi)存占用,同時通過校準(zhǔn)技術(shù)維持準(zhǔn)確率。
三、數(shù)據(jù)處理的關(guān)鍵角色
高質(zhì)量的數(shù)據(jù)處理是量化成功的前提。數(shù)據(jù)預(yù)處理、增強和歸一化能夠優(yōu)化數(shù)值分布,減少量化帶來的偏差。例如,通過數(shù)據(jù)標(biāo)準(zhǔn)化將輸入值縮放到固定范圍,可以避免異常值對量化區(qū)間的干擾。數(shù)據(jù)流水線設(shè)計需與量化策略協(xié)同,確保訓(xùn)練和推理階段的一致性。
四、存儲支持服務(wù)的創(chuàng)新
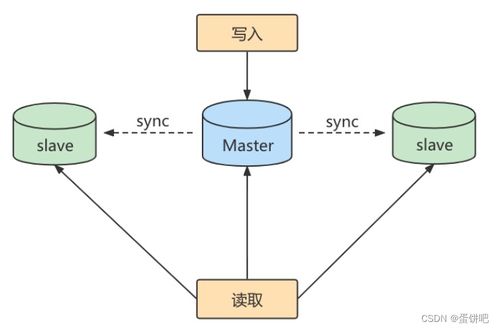
面對海量參數(shù),分布式存儲和高效緩存機制至關(guān)重要。云原生存儲服務(wù)(如對象存儲和內(nèi)存數(shù)據(jù)庫)提供彈性擴展能力,結(jié)合量化后的緊湊表示,可大幅降低存儲成本。例如,采用分層存儲架構(gòu),將高頻訪問參數(shù)置于高速內(nèi)存,低頻參數(shù)存儲于低成本介質(zhì)。新興的非易失性內(nèi)存(NVM)技術(shù)有望進一步打破帶寬瓶頸。
五、未來展望與總結(jié)
神經(jīng)網(wǎng)絡(luò)量化并非萬能鑰匙,需與模型壓縮、稀疏化等技術(shù)結(jié)合。從第一性原理出發(fā),我們應(yīng)持續(xù)探索量化極限,例如1位二值網(wǎng)絡(luò)的潛力。跨學(xué)科合作(如硬件-算法協(xié)同設(shè)計)將推動內(nèi)存墻的徹底瓦解。通過量化、數(shù)據(jù)處理和存儲服務(wù)的深度融合,萬億參數(shù)大模型有望在資源受限環(huán)境中實現(xiàn)高效部署,開啟AI新紀元。
如若轉(zhuǎn)載,請注明出處:http://www.itlovely.cn/product/43.html
更新時間:2026-01-08 02:53:56