智能運維的技術演進之路 數據處理與存儲支持服務的變革
智能運維(AIOps)作為IT運營管理的新興范式,正經歷從傳統人工運維到自動化和智能化的深刻轉變。其中,數據處理與存儲支持服務作為智能運維的核心支柱,其技術演進尤為關鍵。本文將探討智能運維中數據處理與存儲技術的演進路徑,從基礎架構到智能化服務支持,分析其如何驅動運維效率與可靠性的提升。
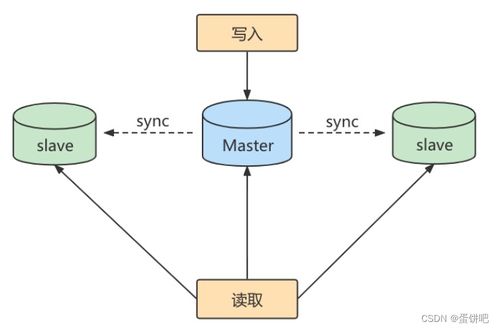
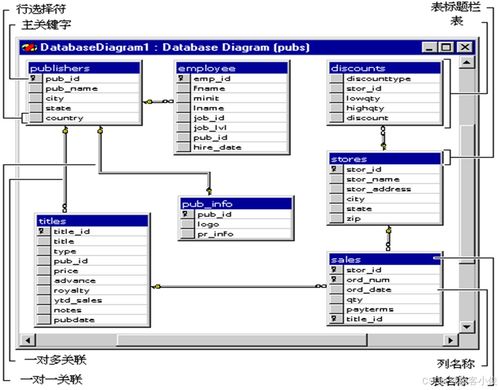
在智能運維的早期階段,數據處理主要依賴于傳統的關系型數據庫和文件系統。運維數據多為結構化日志和性能指標,存儲方案以集中式數據庫為主。這一階段,數據處理能力有限,實時性較差,難以應對大規模、高并發的運維場景。存儲服務的擴展性不足,成為運維自動化的瓶頸。
隨著大數據技術的興起,智能運維進入了數據驅動的新階段。Hadoop、Spark等分布式計算框架的普及,使得運維數據(如日志、監控指標、事件記錄)得以高效處理。非關系型數據庫(如NoSQL)和時序數據庫(如InfluxDB)的應用,解決了海量非結構化數據的存儲問題。數據處理開始支持實時流計算,例如通過Kafka和Flink實現日志的實時分析和異常檢測。存儲服務也從單一中心化向分布式、彈性擴展演進,云存儲和對象存儲(如AWS S3)為運維數據提供了高可用和低成本解決方案。
近年來,人工智能和機器學習的融入,進一步推動了智能運維的數據處理與存儲服務向智能化方向發展。數據處理不再局限于批量或流式處理,而是結合AI模型進行預測性分析,例如通過時間序列預測算法提前識別系統故障。存儲服務開始集成智能分層和自動化管理,利用元數據分析和壓縮技術優化存儲效率。數據湖和數據倉庫的融合,使得運維數據能夠統一存儲并支持多維度分析,為根因分析和決策提供全面支持。
數據處理與存儲支持服務在智能運維中的演進將更加注重實時性、智能化和一體化。邊緣計算與云原生技術的結合,將實現運維數據的就近處理與低延遲存儲;而AI驅動的自治數據庫和存儲系統,有望實現自愈和自適應優化。最終,智能運維將構建起一個高效、可靠的數據基石,支撐IT運營的全面智能化轉型。
智能運維的技術演進離不開數據處理與存儲服務的持續創新。從傳統數據庫到分布式大數據平臺,再到AI賦能的智能存儲,這一路徑不僅提升了運維數據的處理能力,更推動了運維管理從被動響應到主動預防的跨越。未來,隨著5G、物聯網等新技術的普及,數據處理與存儲服務必將在智能運維中扮演更加關鍵的角色。
如若轉載,請注明出處:http://www.itlovely.cn/product/29.html
更新時間:2026-01-08 13:29:13